



Memory and the Arduino
06 June 2016 00:12 Filed in: Electronics
It's been a while since my last post, as I've been deep in a programming project and not working on anything else. It's model railroad-related, and I’ve written a lot of code, but as yet it doesn’t actually do anything and there's nothing really interesting to say about it. I’ll write about it when I actually have it doing something. Maybe next month.
But, as is usual for me, along the way I've tripped over a few of my own misconceptions, and learned a number of useful things. One of the latter is that I now know a heck of a lot more than I really wanted to about Arduino memory use, and in particular about how that changes in the Cortex ARM M0+. Since this version of the Arduino doesn't seem to be well-documented online yet, I thought I'd write up some notes about what I’d learned. This is fairly off-topic for a model railroading blog, but since a lot of what I'm doing these days relates to model railroad control and signaling systems using the Arduino and other microprocessors, it's not entirely off-topic.
And if you skip to the end, you'll find a useful function if you're programming one of these.
My current project uses an AdaFruit Feather, which has the SAMD21G18 version of the ARM Cortex M0+ chip, the same as is used in the Arduino Zero and similar to the SAMD21G portion of the SAMW25 chip used on the new Arduino MKR1000. I don’t have the other two to play with yet, but I think my comments apply equally to all three versions. I’m going to just shorten the name to "M0" for the rest of this post.
The M0 provides 32KB of SRAM and 256KB of Flash memory (but zero EEPROM). That's a lot more than a typical Arduino would have (2 KB of SRAM and 32 KB of Flash), and makes it a useful chip for when you need a bit more than a standard Arduino, without stepping up to a more general computer such as the Raspberry Pi. I have several ideas in mind that can use this extra capacity. It’s also faster by a factor of three, so it can get more done in the same time. And the M0 has more hardware support for some of the standard serial communications methods, which may be useful.
At US$20 the Feather gets me a relatively inexpensive board (Sparkfun has a similar model SAMD21 board for the same price), but the Feather product line also includes some more expensive versions with WiFi, which may help with other things I'm planning. The entry-level Feather isn't as cheap as a Pro Mini, which I can get for less than US$10 these days, and I still plan to use those where they're the right fit. But it’s cheap enough to be interesting.
In addition to my current project, I'm still thinking about control bus applications. A control bus means some kind of networking, and networking protocols tend to require lots of RAM for buffers. An Ethernet shield for an Uno can double the cost, part of which includes local RAM for buffering. There's no Ethernet model of the M0 that I'm aware of (yet, anyway), but there are several with WiFi, at costs not a lot higher than an Uno without networking.
WiFi as the basis of a layout control bus might seem a bit odd, but it definitely has some potential. Layouts are small enough that a private WiFi LAN would likely reach all points on the layout from one central JMRI or similar station, and that would remove any need for more wires. Layouts already have enough wires.
Versions of the M0 with WiFi, like the standard MKR1000, can cost US$45, more than you'd pay for a Raspberry PI 3B with WiFi (US$40), so that's not cheap. There is a US$16 Feather based on an ESP8266 chip (not an M0) with built-in WiFi, which I also plan to look it, and it is the lowest-cost Arduino with WiFi that I'm aware of, but I haven't gotten to that one yet. So I have several options, but to start I'm working with the M0 Feathers.
Cortex M0 Arduino
The M0 is a bit different from the standard Uno chip (the AVR ATmega328 models). For one thing, it's an ARM-family processor rather than an AVR-family processor. This has some low-level implications, which are part of what I stumbled over. As I mentioned, several Arduinos are based on the M0: the Zero, the MKR1000, several of AdaFruit's Feathers, and Sparkfun's SAMD21 board. While the details of pins and other things vary, at heart they're all basically the same processor and have the same memory and processing speed, as mentioned above.
But different processors also have other differences, which affect how existing programs will work. Where an Uno uses 16-bit integers (type “int"), the M0 uses 32-bit ints. And while on an Uno you can read memory for an int starting in any individual byte, on the M0 you can only read on bytes with even addresses (it’s “16-bit aligned” to be technical). Mostly the compiler will hide that problem from you by aligning things properly and wasting an extra byte on padding here or there. But some libraries that work on the Uno won't work on an M0 because of assumptions the programmer made about integer size, alignment or similar hardware details.
It's probably worth mentioning that a lot of what happens in memory doesn't depend on the hardware so much as the software (like the compiler). There are some things that are fixed by the hardware, such as maximum addressable memory and maximum installed memory (which is usually smaller than the maximum addressable by the hardware).
But what goes where depends on the compiler you use and other factors like standard software libraries. I'm using the standard Arduino development environment (IDE), version 1.6.9 at present, and so everything I'm saying here is in that context. The development environment brings some of the standard libraries with it, and thus defines some very basic characteristics of the software (which can also vary between processor models). If you develop using something other than the Arduino IDE, things may be in different places or other limits may apply, or entirely different libraries could be in use.
On the M0, lots of existing libraries work just fine, and for the most part the differences are invisible. Define an array of 100 ints and it takes up 400 bytes of SRAM instead of 200 as on the Uno, but there's so much SRAM that usually isn't a problem. But as described in AdaFruit's tutorial, some things don't work quite the same.
But another difference is that the actual system libraries differ between AVR and ARM, and this has some implications for how things behave. In particular, how Heap memory is managed. I'll get to that a bit later.
Arduino Memory Use
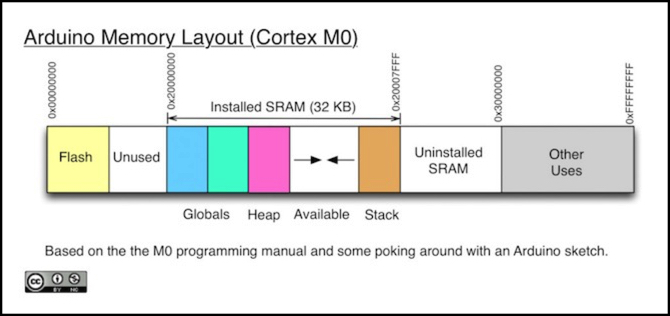
As you're probably well-aware, a standard Arduino like the Uno has three kinds of memory: Flash for the program and non-writeable data you specifically put there when a program is compiled, EEPROM for writeable data that needs to survive a reset or power loss, which a running program can save, and SRAM for writeable data that goes away on a reset or power loss. SRAM is the fastest memory, and it's what's usually meant when someone mentions memory on an Arduino. As mentioned above the M0 has no EEPROM, but that's not the only difference.
Where the Uno and other standard Arduinos use a different mechanism to reference Flash (which is why you need to use PROGMEM to reference data there) the M0 (and other ARM-family chips, like the M3 used in the Arduino Due) use the same address space to reference both SRAM and Flash. This distinction really doesn't affect the issue I want to discuss today, but it's an important difference between the two processors, and makes it a lot easier to use data stored in Flash memory (e.g., tables), since it doesn't need to be copied to SRAM first.
Now to how SRAM is used: this is divided into three sections: at the low end are a collection of "static" variables, both those global variables you define in the sketch outside of functions and and ones defined elsewhere using the "static" keyword, including those the system creates when libraries are used (like the serial buffer used for Serial.print()). This is followed by an area called the Heap (we'll come back to that in a bit), then there's a gap of available memory, and at the top of SRAM there's an area called the Stack.
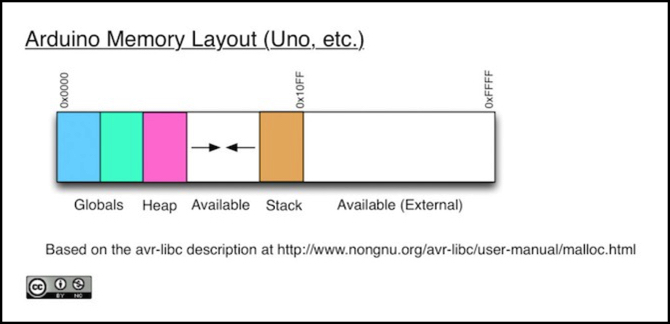
Now all of that is in the built-in SRAM. The Arduino also allows for add-on RAM, at least on the Mega model (and apparently there were a couple of shields for that, although I never used them and they may be out of production now). Any add-on SRAM is in a separate portion of the range of memory addresses, stuck on the end beyond the built-in memory. That goes in the "Available (External)" range in the diagram above.
If you aren't familiar with computer memory addresses one thing that might not be obvious is that these addresses are the addresses of bytes (a byte is 8 bits). Even though an Uno normally grabs memory in 16-bit chunks, it can grab them starting at any byte. The M0 normally grabs memory in 32-bit chunks, starting on an "even" byte number, but it still uses addresses of individual bytes.
Memory addresses on the Uno are 16 bits (hex 0x0000 to 0xFFFF), allowing up to 64 KB of memory. Memory addresses on the M0 are 32 bits (0x00000000 to 0xFFFFFFFF), allowing up to 4 GB in theory, although the lack of external addressing pins limits this to built-in memory. As with the Uno, this is broken up into several logical sections. And similarly, there are a whole lot of addresses that don't point to anything useful (because 4 GB is a heck of a lot of memory for an embedded processor).
All those addresses let the M0 use addresses differently. In addition to those used for SRAM, some addresses are set aside for Flash so that can be referenced directly, and some are used for device control via Direct Memory Access (DMA), a topic I won't get into here, but another important difference in the processor.
Let's take a concrete example using simple global variables. A simple test program I wrote for the Arduino uses the first 280 bytes of SRAM for its own purposes, like the Serial buffer (individual programs may use more or less depending on what they're doing; much also depends on what libraries you include). Those 280 bytes occupy addresses 0x0000 to 0x0117 (0x0118 is 280 in decimal). If we define a pair of global integers as:
int firstInt;int secondInt;firstInt will be assigned memory starting at the next available byte, which is 0x0118. On an Uno, an int is 16 bits (two bytes), so secondInt is assigned memory starting at 0x0118 + 2 = 0x011A, or 282. On the M0 an int is 32 bits (four bytes), so secondInt is assigned memory starting at 0x011C (284), or rather at 0x2000011C since the M0 uses longer addresses and starts SRAM at a location above zero. As we assign more variables to global space they get added similarly.
If you want to see where a variable is assigned memory, use a command like the following:
Serial.print((unsigned int) &firstInt, HEX);which will print out the address of the first byte assigned for use by firstInt.
All of the global space is assigned "statically", meaning it doesn't change once the program starts running. All of those addresses are assigned when the program is compiled, even before it is loaded into the Arduino. That's also true of addresses in Flash on the M0. Among other things, this means that arrays here can't be made longer once the program is running.
The most common reason new Arduino programmers run out of memory is putting string constants in their programs, which are static and thus end up using global memory, such as:
Serial.print("Hi there, I'm a string constant taking up 69 bytes of precious SRAM.");This is why the F() macro was added to Arduino, because it lets you shift some of those constants into Flash:
Serial.print(F("Hi there, I'm a string constant in Flash memory, so only a small buffer is used in SRAM."));Behind the scenes, the F() macro causes the string to be stored in flash and a function to be called by Serial.print that copies the string into SRAM using a buffer (so some SRAM is used, but much less than would be needed for a bunch of strings). On the M0, you don't actually need the F() macro for this, because it puts string constants into flash automatically, but it's still a good idea to use it for portability.
BTW, compilers are very good at optimizing memory. If you just define firstInt and secondInt as above and never use them, they won't actually be assigned any memory at all. And depending on how you use them, the compiler might decide that they don't need any memory (it can keep ints in internal registers if they're only needed briefly, and will do so if it can, to make the program run faster).
I tripped over this when I was testing dynamic memory, after creating hundreds of bytes of variables I found that my memory size hadn't increased at all. Which puzzled me until I realized that it was the compiler being "helpful". Then I added some code to put time stamps from millis() into the variables as they were created, and to use that later, and then suddenly my program was using a lot more memory.
Stack
Now lets look at the stack. It gets assigned memory starting from the top of the actual installed memory. When it needs to grow, it takes memory from the free area below it (the left-pointing arrow in the diagram above). A special register, called a "stack pointer" keeps track of the next address to use for the stack. On the M0, there's a function that will tell you the current value of the stack pointer. You can call this in a print statement if you define it as:
extern uint32_t __get_MSP(void); // two underscores before the "get"Note: the M0 actually has two stack pointers, but the Arduino environment only uses the Main Stack Pointer (MSP).
Notice that the type is "uint32_t", that's a formal shorthand for saying "unsigned 32-bit int". Since the M0 uses 32-bit ints, you could replace it with "unsigned int" in the definition, however it's generally considered good form to be specific about the number of bits in situations where it matters. That can cause compiler or linker errors if you try to use the same code on something other than an M0, but in general you want that to happen, to remind you to go look at the code and be sure you weren't making assumptions about the size.
At the same time, sometimes it's more flexible if you don't get specific. Remember the print command up above that shows the address of a variable? Because that uses "unsigned int" it will work properly on both an Uno and an M0, because on both addresses are the same size as unsigned ints, even though the two processors use different sizes. However, even better than "unsigned int" is "size_t", as that's an unsigned quantity guaranteed to be large enough to hold the size of the largest possible object, even if that differs from an integer.
Note: on some architectures the size of a pointer variable can be different from the size needed to hold the number of bytes, and there’s actually a special type for when you need to do pointer math, called ptrdiff_t. I probably ought to use ptrdiff_t some of the times I use size_t, but on the Arduino processors used to date, they’re the same size.
The stack is used when functions are called. It holds information needed for this call to the function (space for any "by value" parameters, addresses (pointers) for any "by reference" parameters, and space for any local or "automatic" variables within the function). When the function exits and control returns to the caller, the stack pointer is moved back to what it used to be, releasing all of the memory back to the available pool. Very simple and efficient. And foolproof; you can’t “leak” stack memory by misplacing it.
Let's take a look at what this means: assume we're on an Uno, where the stack started at 0x10FF, and further assume that we've already used 256 bytes of stack, moving the pointer down to 0x0FFF (that's 0x10FF - 256). Now we call a function that needs a total of 20 bytes on the stack.
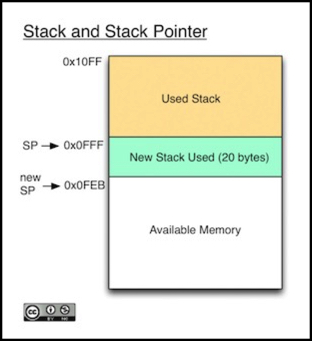
In the diagram, the green-tinted memory is the 20 bytes assigned for this function call. It's kept around and used as long as the function is running, and if the function calls another function, the next block of stack will be assigned starting at 0x0FEB (that's 0x0FFF - 20). Once the current function exits, the stack pointer gets set back to 0x0FFF and all of the green memory is no longer in use. As you can see, memory on the stack can only be added or removed by the activity of functions being called or exited, because if anything on the stack had to be kept after a function exited, it would be impossible to move the pointer back.
On the M0 (as used by the Arduino), the stack starts at the top of the 32 KB of SRAM, or at address 0x20007FFF).
The Heap
The other big subdivision of SRAM is the heap. The reason we have a heap is that sometimes you need to create a variable, but don't know how large it will be (or how many of them there will be) until the program is running. Both the globals (static variables) and stack (automatic variables) have sizes that are fixed at compile time, long before the program runs.
The ability to create "dynamic" variables, those created on-the-fly as needed, is a very powerful tool in computing. Like any power tool, it needs to be treated with respect or it will hurt you, or rather hurt your program.
The heap is used for variables created using malloc() or new() to reserve memory. The heap is assigned memory above the globals (remember that the globals are fixed in size and can't grow, so that's safe to do). When the heap needs more memory, it takes it from the unassigned pool above it. This is the same pool used by the stack, but the heap and stack take their memory from opposite ends, so as long as the two of them together don't use it all up, that's not a problem.
On an Uno, the heap and stack start out roughly 2,000 bytes (2KB minus some overhead) apart and grow towards each other. On the M0 they start out 32 KB apart and behave the same. The space between them is often referred to as the "available RAM" and for the Uno there's even a freeRam() function (bottom of linked page) to display this. It doesn't compile on the M0; one of those "different system library" problems I mentioned earlier, because a symbol it depends on is missing. I’ll fix that by the end of this post.
However, there's a similar function referenced by Adafruit's tutorial (originally from a post on the Arduino forum) that will work on the M0 (I made a couple of changes to the function name and result type to suit my preferences, but the original actually compiles just fine):
extern "C" char *sbrk(int i);size_t freeRAM(void){ char stack_dummy = 0; return(&stack_dummy - sbrk(0));}So you can detect how much memory is unassigned in the gap between the stack and the heap. But that's not the whole story.
Memory on the heap is assigned by malloc() or new(), and released by free() or delete(). But unlike the stack, the heap never shrinks, even when memory is released.
In more sophisticated computers and languages, heap memory can be "garbage collected" to make it smaller. C and C++ (the Arduino "language" is really C++) do not have garbage collection, and there's no separate operating system on an Arduino to help out.
I'm not really a C programmer. I learned programming in another language, and while I'm comfortable with C, my knowledge is self-taught and has gaps. This turned out to be one of them, and the fact that C heaps never shrink took me by surprise.
Let's say you have a running program on an Uno. You start out with roughly 2KB of "free" memory. You allocate a bunch on the heap totaling 1.5 KB and then free() it, how much freeRam() do you have? The answer is 0.5 KB, not 2 KB.
Now there's really 2 KB of unused memory, but 1.5 KB is now locked up in the heap, which is never going to give it back. That 1.5 KB can be used by malloc() or new(), so technically it's "free", but it can never be used by the stack. Since freeRam() shows the space between the ends of the stack and the heap, and the end of the heap is at 1.5 KB, it's showing the space between correctly as 0.5 KB (and it can never be larger than that).
What freeRam() really shows then, is the safety margin for stack use. That's a useful number to have, and in many cases more useful than total free SRAM, but the name is more than a little misleading.
The reason I call this the "safety margin" is that the stack is constantly getting larger and smaller as functions are called and exited. Unless you have some kind of runaway recursion loop, there's a maximum amount it will ever use, although it may not reach that peak normally or often, and actually figuring out just what that maximum would be is very difficult. If the heap gets too close to the stack, some odd condition that causes the stack to grow to that maximum might cause the two to collide. When that happens, data is corrupted, and the data could be an address on the stack. Programs usually fail in very odd ways when they "run out" of memory like that.
So it's a really good idea to have a reasonably large pool of memory between stack and heap, to allow room for unexpected stack growth. That's a "safety margin". And it’s why having a freeRAM() function is so useful: during development you can use it to check on how your memory is being used, to make sure you will avoid any problems.
Lets look more closely at the heap. The following diagram shows the state of the heap after some memory has been assigned, and some of that has been freed. Green tint shows memory still in use, yellow shows freed, and white shows never-assigned memory.
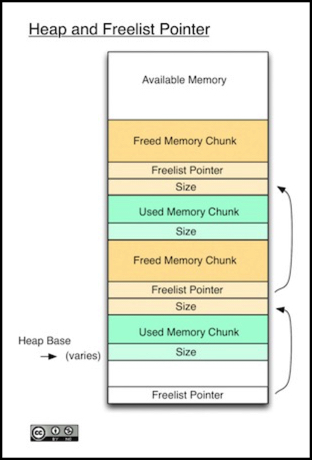
Heap memory is initially assigned from the bottom up, taking memory above the “heap base” location, which as you’ll recall is above the global and static variables, so the exact location changes from one program to another. Slightly below the heap base is a freelist pointer, which starts out as a NULL pointer since initially there’s no memory in the heap at all, much less any that’s been free()’d.
When memory is assigned, first the freelist is checked. If the size of any block on it is sufficient to hold the requested memory, the needed memory is taken from that block. If the block is large enough, what’s left gets put back on the freelist as a new free block, otherwise it will just be stuck on the end of the requested memory. The size number counts the total size of the memory chunk, including itself and any unused space on the end. This is not the “size” requested by the caller. If the whole freelist is checked and no chunk large enough exists, memory directly above the heap is taken from available memory (there’s another pointer that points to the heap top so we know where that is).
Notice that there’s no equivalent of the freelist for assigned memory. Assigned memory is given to the caller, to use as they see fit, and it’s up to the caller to keep track of it. If they overwrite their pointer or otherwise forget about a chunk of memory, it’s permanently lost, a “memory leak”. The memory is still there, of course, but no part of the program remembers where it is, so it will never be used or recovered.
When a used chunk of memory is freed by the caller, it’s placed into the free list. The freelist is ordered by address, so if the new chunk is next to a pre-existing freed chunk, that is easily detected and the two are merged into one big chunk. Otherwise it’s a separate chunk on the list.
There’s one more form of wastage: on the M0, a number (like Size) must start on an even byte boundary. For reasons known only to the library developers they chose to require starting heap chunks on a “divisible by 4” boundary. Thus if the end of a block isn’t divisible by four, up to three more bytes will be added to the block so that the next chunk’s size variable starts in the right place.
And finally, note that when an unused chunk is that last one on the list and is adjacent to the available memory it remains on the freelist. They could have chosen to return it to the available memory pool and shrink the heap, in the same way adjacent free chunks get merged, but for some reason the library programmers did not.
As you can see in the diagram above, the freelist pointer is just the first portion of the assigned memory (this is the M0 version, so both size and the pointers are 32-bit quantities). That means that size counts the pointer (since it’s part of the chunk). To find out how much unused memory is in the heap you simply run down the freelist and add the sizes. That doesn’t mean you can necessarily use all of it, because it’s in a collection of smaller chunks that won’t necessarily be used efficiently, and some of it goes to size counters and alignment. But that’s the amount that’s been taken away from the available memory but isn’t actually being used.
This is useful because you can compare it to what’s been taken and freed. If you free everything, then the sum of the freelist and the safety margin should be the same as it was before you started.
This can be a useful technique for finding memory leaks. That’s actually what got me started down this path in the first place. I wanted to check the freelist to confirm I wasn’t leaking memory and the function I’d normally use on an Uno wouldn’t work. Once I had the function, I found that I did have a memory leak (I said they were easy to create). Knowing that, I eventually tracked down the place where a pointer was getting overwritten before it was free()’d. I’m not sure I could have found it if I didn’t know I had to look.
Using Dynamic Memory Safely
In a memory-limited system like an Arduino, using dynamic memory is very risky over the long term, as the heap will gradually eat away at the relatively small safety margin due to internal "fragmentation" and possibly also due to memory leaks. For this reason you'll often see people online saying that you should never use dynamic memory on an embedded processor like an Arduino. That’s not really wrong. If you want a list of why dynamic memory on an embedded processor is a bad idea, here is a good summary, along with some comments on when (and how) you could use it if you had to.
Not using the heap at all is bit extreme, and often experienced programmers will say that on an embedded processor, the best approach to use of dynamic memory is to use it as needed when the program starts up to request all that you need, and then stop requesting more. You don't need to bother freeing it, since that probably won't help, but as long as you stop asking for more, the program should never run into memory limits later, no matter how long it runs.
There's an implication to this: C++ objects are tightly linked to use of dynamic memory. You need to be very careful when using objects not to also use dynamic memory, and you may not be aware of all uses because some operations on existing objects will create new ones. For stability, avoiding any use of objects in a memory-limited environment like the Arduino is probably a good idea. However, on Arduino essentially all libraries are implemented via objects, so you can't avoid them entirely.
Sometimes you can't avoid using dynamic (heap) memory for other reasons. If you can't, you need to understand that you are taking a risk with the stability of your program, and that over a long interval that could lead to it crashing no matter how much care you take. Maybe that's acceptable, depending on your application. Many programs don’t need to run forever. But when they do, there are certainly things you can do to improve stability.
One of the common users of heap memory is the Arduino String library, and things based on it. When you use String variables (strictly speaking you are using objects of class String) and perform operations, you are really creating new strings in the heap (sometimes more of them than you think). A program that continually performs operations on String variables can sometimes leave a few of them behind (memory leaks), and gradually eat away at free memory. Even if it doesn’t, it’s creating fragments of freed heap memory that may be quite small and hard to reuse unless they end up adjacent to each other or some other freed memory. There's a good description of how Strings can hurt you here, along with some discussion of alternatives.
An alternative to using Strings is to do your own manipulation of standard C strings (null-terminated character arrays). But of course since arrays in global or stack space can't change size, you either need to use larger-than-necessary arrays (and be careful not to exceed them; it's a good idea to use strlcat and strlcpy rather than strcat/strcpy, as discussed here) or do your own management of heap space using malloc and free (or new and delete, but on an Arduino those simply call malloc and free so if you aren't using objects there's no advantage to them). Doing your own management opens up the risk of memory leaks if you lose track of something (which is surprisingly easy to do), but if you’re careful that’s probably less risk than using a String object.
The oversized-array approach is wasteful of memory, and thus in some situations it's not the best choice, but a lot of the time wasting a few dozen bytes is a small price to pay for stability. I'll do my own dynamic memory management at times, paying great care to how I use and free things, but usually I'll go for the array approach. I never use String objects.
Heap Differences
All of this brings me to the difference between the heap on an Uno and the heap on an M0. Now first, they're very similar. But they're not identical. That same page that defined freeRam() for the Uno also has a freeListSize() function, that actually goes through the heap and counts freed-up memory, to provide a better indication of how much memory is really available if you've been creating and free()'ing dynamic memory. Like the standard freeRam(), it won't compile on an M0. Or rather, both compile but won't link, because they're referencing something that doesn't exist on that system.
The problem is that AVR family processors use a standard open-source library (avr-libc) for a bunch of common functions, including heap memory management. This defines several standard pointers for the heap (see this page for details). The M0 uses a very similar approach to heap management, but it's not identical, and a couple of the symbols (like the free list pointer and top-of-heap pointer) aren't the same, which is why the two functions that depend on them generate errors if you try to use them.
The reason the M0 doesn't use avr-libc is that it's not an AVR-family chip, and so its hardware is not one of the many models supported by the avr-libc project.
After a bit of searching for the source file that contained either malloc() or the freelist pointer for the Feather, and not finding it, I hit on the idea of looking through a compiled sketch using readelf to see if I could find a symbol that looked like a freelist pointer. It was pretty obvious, a 4-byte global named "__malloc_free_list". There was also "__malloc_sbrk_start", which appears to point to the fixed base of the heap. I couldn’t find a pointer to the top of the heap.
Those two symbol names make it obvious that the Feather is using some variant of the ARM version of newlib for its memory management. That's not really surprising, as it's a fairly common library to use for an embedded processor. It doesn't seem to be the standard version, as it's aligning to four-byte boundaries, and the standard one seems to default to eight-byte boundaries, plus the source file seems to have some other name than the usual (or I'm really bad at searching by file names).
It turns out that the free list structure is essentially the same, allowing for the larger address lengths.
I did find one error though (or perhaps a difference between the two memory management systems). The original freeListSize() function added 2 bytes "for the memory blocks header", and I found that on the M0 anyway, this was counted in the freelist size, as shown in the example diagram above. I haven't looked at the Uno memory management as closely so I’m not sure why or how that differs. I also made a couple of minor changes, such as switching to the more portable size_t from int, but in the end my version wasn't much different from the original:
struct __freelist { size_t sz; struct __freelist *nx;};extern uint32_t *__malloc_free_list; // head of the free listsize_t freeListSize() { struct __freelist* current; size_t total = 0; for (current = (struct __freelist *) __malloc_free_list; current; current = current->nx) { total += (size_t) current->sz; } return total;}Heap Observations
Using freeListSize(), it's pretty clear that when it can, free() does a very good job of returning memory and combining adjacent blocks into one larger block (I stuck in some Serial.print statements so I could see the sizes of individual blocks being added). Even randomly deleting items out of a list of created objects, if I saw the safety margin shrink by N bytes when they were created, after freeing them the freelist contained exactly N bytes of available memory. That doesn't mean that fragmentation can't happen, but it does mean that carefully managed, there's a very good chance that freed memory can be reused for new objects. And it means that when the numbers don’t match after freeing eveything, it’s time to look for a leak.
The other thing to be aware of is that, as I described above, when malloc() or new() creates a dynamic memory object, it needs to record some information about that object (the size), and it will need to align the object to a 32-bit boundary (on the M0 anyway). At a minimum, 4 bytes of overhead are created for the object, but up to 7 may be. You get all that back when it's freed, of course, but it does mean that using dynamic memory just to save a few bytes per object isn't going to work. If you can make the object 4 to 6 bytes larger, and static, you should break even on memory use and avoid any risk of instability. Even if it needs to be somewhat larger than that, the stability advantages of using fixed memory rather than dynamic may be worth it.
Where dynamic memory really wins is when you need to create a bunch of things that can potentially be very large but usually aren’t. An example would be reading a file of configuration keywords and values, where each keyword/value pair might be 256 bytes in length, but probably is closer to a tenth of that size. If you load a config file (e.g., off an SD memory card) at startup, using heap to store the config is both efficient and a one-time activity. But any memory you use to do that is effectively gone forever, so you have to plan for that. If you assign and give it back carefully (i.e., without mixing in any other assignments you won’t give back) you’ll end up with one big chunk on the freelist, but it is on the freelist, and not in the available pool used by the stack.
Summary
Now that I've fought my way through all of that, which took over a week of evenings and weekend hobby time, I now know how to determine how much memory is both free in the heap and available in the "safety margin" between heap and stack. That's a very handy tool in my toolkit as I continue development. Compared to the Uno's 2 KB, the 32 KB on an M0 seems like a lot, but it's surprisingly easy to burn through it. I have one sketch already using more than half of it. And, as I mentioned, I’ve already used it to find one programming error that was causing a memory leak.
The other thing that I learned, quite to my surprise, was that free() (and delete()) didn't put memory back into the general-use pool, but only released it to a pool usable by malloc() (and similar routines). That’s “standard” C behavior, but it surprised me, and it affects some of what I was planning to do on one program.
So this weeklong detour has proven to be very productive for me, more so than it seemed it would be at times. Now I can get back to the library I was working on, which was itself a detour from the actual program I'm trying to write. Progress is slow at times, but I do seem to be generally moving ahead.